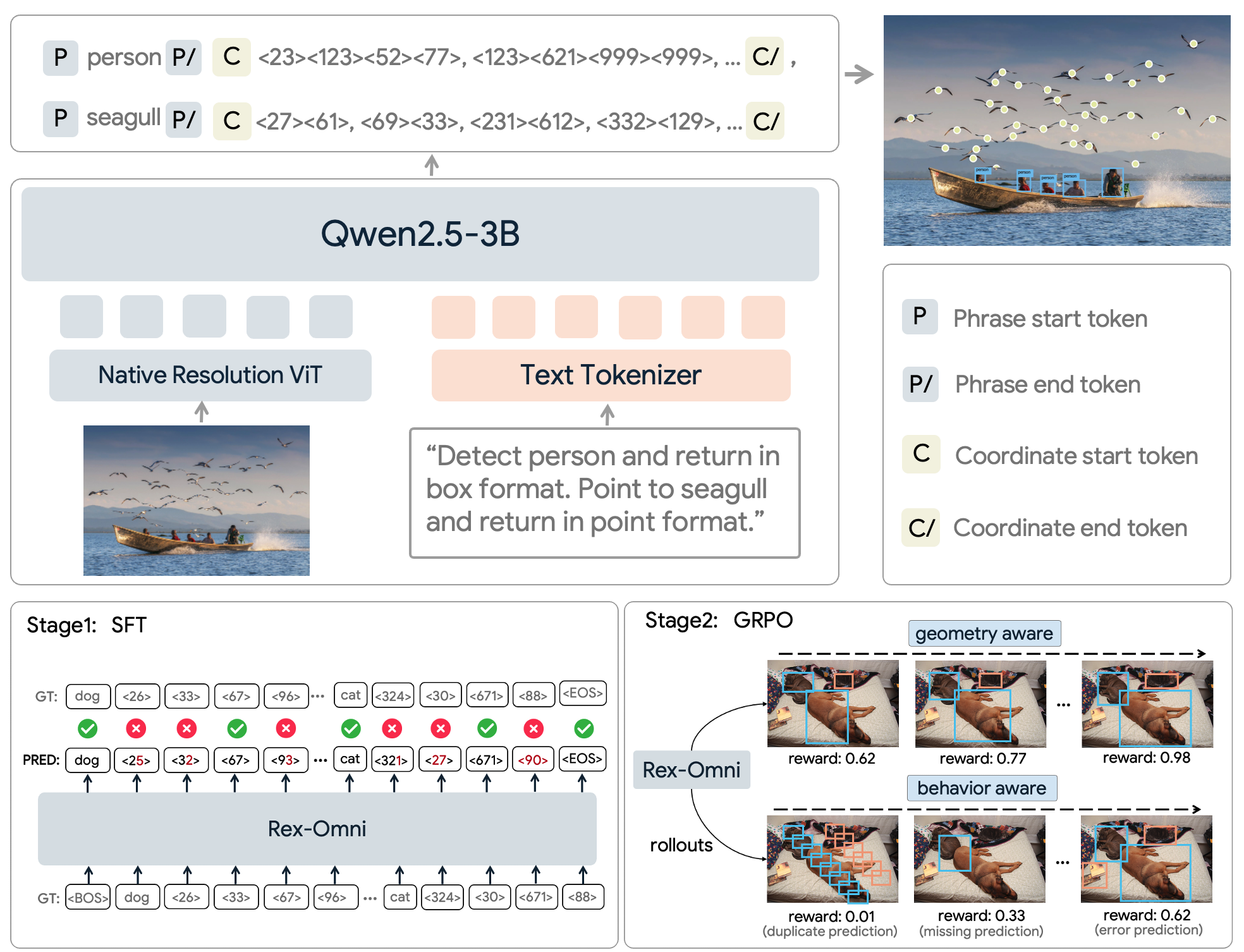
Unified architecture for multiple vision tasks
Next point prediction framework
Rex-Omni reformulates visual perception as a next point prediction problem, unifying diverse vision tasks within a single generative framework. It predicts spatial outputs (e.g., boxes, points, polygons) auto-regressively and is optimized through a two-stage training pipeline—large-scale Supervised Fine-Tuning (SFT) for grounding, followed by GRPO-based reinforcement learning to refine geometry awareness and behavioral consistency.
3B
Parameters
10+
Vision Tasks
1
Unified Model